이 포스팅은 "딥러닝을 이용한 자연어 처리 입문"에서 인용한 내용 및 이미지를 담고 있습니다.
1. BiLSTM
BiLSTM은 양방향 LSTM이라고도 하며 두 개의 독립적인 LSTM 아키텍쳐를 함께 사용함

주황색 LSTM은 앞에서부터 순차적으로 입력받고, 초록색 LSTM은 뒤에서부터 역방향으로 입력을 받음
즉, 양쪽으로 보면서 양문맥을 다 고려하겠다는 것임
출력층에서 두 가지 정보를 모두 사용함
위 그림은 many-to-many 문제를 푸는 경우이고, many-to-one 작업을 할 시에는 처음 혹 마지막에 출력층을 두면 둘 중 하나는 부족한 정보를 가지고 있을 것이기 때문에

이렇게 출력층에서 각 LSTM의 마지막 은닉상태를 사용함
2. CRF
CRF 층은 이전부터 독자적으로 존재했던 모델인데, 보통 BiLSTM 위에 추가해서 NER같은 태스크를 진행하는 상황에서 자주 같이 쓰임
여기서 CRF가 어떤 역할을 하는지 직관적으로 살펴보자면
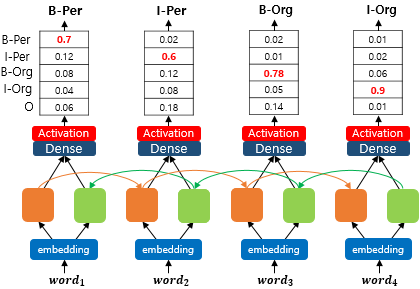
위와 같이 간단한 NER을 진행해본다고 치면, B-Per 뒤에 I-Per 이 있고, B-Org 뒤에 I-Org가 있어서 정확한 예측인지 위 그림만으로는 알 수 없지만 순서는 일단 맞음

근데 이 그림에서는 개체명들이 틀릴 수 밖에 없는 예측임. I-Org 뒤에는 I-Per이 나올 수 없고 I-Org도 B-Org 없이 독자적으로 나올수가 없기 때문,, BIO 표현 방법의 제약사항을 모두 위반한 상태임
여기서 BiLSTM에 CRF를 추가하면, 모델이 예측 개체명(=레이블) 사이의 의존성을 고려할 수 있음.

CRF layer에 각 활성화 함수의 결과들이 입력으로 전달됨. 그러면 CRF 층에서 레이블 시퀀스에 대해 가장 높은 점수를 가지는 시퀀스 예측함. 이러한 과정에서 CRF 층은 점차적으로 문맥적인 제약사항을 학습하게 됨.
- 문장의 첫번째 단어에서는 I가 나오지 않습니다.
- O-I 패턴은 나오지 않습니다.
- B-I-I 패턴에서 개체명은 일관성을 유지합니다. 예를 들어 B-Per 다음에 I-Org는 나오지 않습니다.
따라서, BiLSTM은 '입력 단어'에 대한 양방향 문맥을 반영하고, CRF는 '출력 레이블'에 대한 양방향 문맥을 반영함
'NLP' 카테고리의 다른 글
| [Langchain] LLM/BitsandBytes 기반 Quantization LLM + Langchain 함께 사용하기 (1) | 2024.04.24 |
|---|---|
| [GPT] Generation 코드 탐험기 (+ generation param 설명) (0) | 2024.02.12 |
| GLUE TASK (0) | 2022.12.15 |
| 표 기계독해에 다중 도메인을 적용하는 방법 3가지 (0) | 2022.11.22 |